
Zstandard
Zstandard (zstd)는 Facebook에서 개발한 압축 알고리즘 이다.
Zstandard, or zstd as short version, is a fast lossless compression algorithm, targeting real-time compression scenarios at zlib-level and better compression ratios.
It also offers a special mode for small data, called dictionary compression.
It's backed by a very fast entropy stage, provided by [Huff0 and FSE library](https://github.com/Cyan4973/FiniteStateEntropy).
Zstandard's format is stable and documented in [RFC8878](https://datatracker.ietf.org/doc/html/rfc8878).
Multiple independent implementations are already available.
적용의 예
https://en.wikipedia.org/wiki/Zstd#Usage
- In March 2024, Google Chrome version 123 added zstd support in the HTTP header Content-Encoding.
- In May 2024, Firefox release 126.0 added zstd support in the HTTP header Content-Encoding.
- On 15 June 2020, Zstandard was implemented in version 6.3.8 of the zip file format with codec number 93.
- In May 2018, Fedora(release 28) added ZStandard support to RPM and used it for packaging the release in October
- 2019 (Fedora 31). In Fedora 33, the filesystem is compressed by default with zstd.
- In 2018 the algorithm was published as RFC 8478, which also defines an associated media type "application/zstd", filename extension "zst", and HTTP content encoding "zstd".
...
특징
zstd는 CPU 성능을 효율적으로 사용하여 빠른 압축 및 해제 속도를 제공한다. 특히, 낮은 압축 레벨에서는 매우 빠르게 작동하며, 높은 압축 레벨에서는 상대적으로 더 높은 압축률을 제공한다.- -1부터 22까지의 다양한 압축 레벨을 지원한다. 기본 값은 3이며, 이 값은 대부분의 경우 적절한 성능과 압축률을 제공한다. 낮은 숫자는 더 빠르지만 압축률이 낮고, 높은 숫자는 느리지만 압축률이 더 높다.
- 압축 및 해제 시 메모리 사용량이 효율적으로 관리되므로, 임베디드 시스템이나 메모리 제한이 있는 환경에서도 유용하다.
- dictionary를 사용할 수 있어, 데이터가 반복되거나 패턴이 명확한 경우에 더 높은 압축률을 얻을 수 있다. 이는 특히 네트워크 통신이나 특정 패턴이 자주 나타나는 경우에 유리하다.
- 스트리밍 데이터를 효율적으로 처리할 수 있도록 스트리밍 압축/해제를 지원한다.
-# : # compression level (1-19, default: 3)
--ultra : enable levels beyond 19, up to 22 (requires more memory)
--long[=#]: enable long distance matching with given window log (default: 27)
--fast[=#]: switch to very fast compression levels (default: 1)
--adapt : dynamically adapt compression level to I/O conditions
기술적 특징
LZ77 기반의 알고리즘과 Entropy coding 기법을 조합하여 데이터의 중복을 제거하고 효율적으로 데이터를 표현하여 크기를 줄임으로써 높은 압축률과 빠른 속도를 달성했다.
LZ77 기반 매칭 (Lempel-Ziv 77)
LZ77은 데이터를 반복되는 패턴으로 탐지하고, 해당 패턴을 참조(reference)하여 중복된 데이터를 제거한다.
- 매칭(match) 탐지: LZ77에서 압축할 데이터 스트림은 슬라이딩 윈도우(sliding window) 방식으로 처리한다. 슬라이딩 윈도우는 현재 위치에서 이전에 나온 데이터를 비교하면서 동일한 패턴(매칭)을 찾는다.
- 복사(reference) 지시어: 매칭이 감지되면, 데이터가 반복되는 위치와 길이를 참조하는 방식으로 데이터를 압축한다. 즉, 직접 데이터를 기록하는 대신 이전에 발생한 위치와 길이를 참조한다.
- 리터럴(literal): 패턴이 발견되지 않는 경우에는 해당 데이터를 그대로 기록한다.
이 과정에서 dictionary를 사용하는 경우, 사전에서 미리 정의된 패턴을 참조할 수 있어 압축 효율을 높일 수 있다.
Entropy coding
https://en.wikipedia.org/wiki/Entropy_coding
https://datatracker.ietf.org/doc/html/rfc8878#name-entropy-encoding
Two types of entropy encoding are used by the Zstandard format: FSE and Huffman coding. Huffman is used to compress literals, while FSE is used for all other symbols (Literals_Length_Code, Match_Length_Code, and offset codes) and to compress Huffman headers.
Zstandard는 LZ77 방식에서 발견한 매칭 정보와 리터럴을 효율적으로 표현하기 위해 FSE(Finite State Entropy)와 Huffman Coding를 사용한다.
FSE (Finite State Entropy): 범용 엔트로피 코딩 기법보다 더 빠르고 효율적인 상태 전이 기반의 엔트로피 인코딩이다. 이는 주어진 심볼들의 출현 확률에 따라 더 짧은 비트로 표현할 수 있는 심볼에 적은 비트를 할당해 데이터를 압축한다.
https://datatracker.ietf.org/doc/html/rfc8878#name-fse
Huffman coding: FSE 이전에 주로 사용된 엔트로피 코딩 방식으로, 빈도에 따라 데이터 심볼을 가변 길이 비트로 인코딩한다. Zstandard는 FSE와 함께 Huffman coding을 사용하여 데이터 심볼을 더욱 효율적으로 표현한다.
https://datatracker.ietf.org/doc/html/rfc8878#name-huffman-coding
멀티스레딩 및 블록 처리
Zstandard는 데이터를 블록 단위로 처리하여 병렬 처리가 가능하다. 압축 과정에서 데이터를 작은 블록으로 나누고, 각 블록을 독립적으로 처리할 수 있어 멀티스레딩 성능을 극대화할 수 있다. 이렇게 하면 대규모 데이터 세트에서도 빠른 압축 속도를 유지할 수 있다.
블록 크기
기본적으로 Zstandard는 각 블록 크기를 최적화한다. 데이터의 특성에 따라 최적의 블록 크기를 결정하며, 블록이 너무 작거나 크면 압축률이나 성능에 영향을 미칠 수 있다.
https://datatracker.ietf.org/doc/html/rfc8878#name-frames
Zstandard compressed data is made up of one or more frames. Each frame is independent and can be decompressed independently of other frames. The decompressed content of multiple concatenated frames is the concatenation of each frame's decompressed content.
There are two frame formats defined for Zstandard: Zstandard frames and skippable frames. Zstandard frames contain compressed data, while skippable frames contain custom user metadata.
https://datatracker.ietf.org/doc/html/rfc8878#name-blocks
Each frame must have at least 1 block, but there is no upper limit on the number of blocks per frame.
Dictionary
Zstandard는 dictionary 기반 압축을 지원한다.
dictionary은 반복적으로 발생하는 패턴이나 데이터 구조를 미리 학습한 데이터이다.
dictionary 생성: 특정 도메인의 데이터(예: 로그 파일, 네트워크 패킷 등)를 대상으로 미리 dictionary를 생성하고, 이를 통해 해당 도메인에서 발생할 가능성이 높은 데이터 패턴을 압축에 사용한다.
dictionary 압축: dictionary가 존재하면 데이터를 압축할 때 dictionary의 데이터를 참조하여 더 높은 압축률을 얻을 수 있다. dictionary 기반 압축은 특히 작은 크기의 데이터 압축에서 효과적이다.
https://datatracker.ietf.org/doc/html/rfc8878#name-dictionary-format
The case for Small Data compression
https://github.com/facebook/zstd?tab=readme-ov-file#the-case-for-small-data-compression
압축할 데이터의 양이 적을수록 압축하기가 더 어려워진다. 이 문제는 모든 압축 알고리즘에 공통적으로 나타나는데, 그 이유는 압축 알고리즘이 과거 데이터를 통해 미래의 데이터를 압축하는 방법을 학습하기 때문이다. 하지만 새로운 데이터 세트가 시작될 때는 '과거'라는 기반이 없다.
이러한 상황을 해결하기 위해 zstd는 선택한 데이터 유형에 맞게 알고리즘을 조정하는 데 사용할 수 있는 training mode 를 제공한다. 몇 개의 샘플(샘플당 하나의 파일)을 제공하면 Zstandard를 훈련시킬 수 있다. 이 훈련의 결과는 압축 및 압축 해제 전에 로드해야 하는 "dictionary"라는 파일에 저장된다. 이 dictionary를 사용하면 작은 데이터에서 달성할 수 있는 압축률이 크게 향상된다.
학습(Training)은 작은 데이터 샘플 모음에 어느 정도 상관관계(correlation)가 있는 경우에 효과적이다. 데이터에 특화된 dictionary 일수록 더 효율적입니다(there is no universal dictionary). 따라서 데이터 유형당 하나의 dictionaryfmf 배포하는 것이 가장 큰 이점을 제공한다. 사전의 이득은 대부분 처음 몇(first few) KB에서 효과적이다. 그런 다음 압축 알고리즘은 점차적으로 이전에 디코딩된 콘텐츠를 사용하여 파일의 나머지 부분을 더 잘 압축한다.
trainging mode 를 테스트 해볼수 있는 예제.
https://github.com/facebook/zstd/releases/tag/v1.1.3
Download and expand sample set
$ wget https://github.com/facebook/zstd/releases/download/v1.1.3/github_users_sample_set.tar.zst
$ zstd -d github_users_sample_set.tar.zst
$ tar xf github_users_sample_set.tar
$ ls
github github_users_sample_set.tar github_users_sample_set.tar.zst
$ ls github
user.000P9V4UUS.json user.69DNEofHUA.json user.B9r8huafLd.json user.EcIHPzyby7.json user.HkifKxq2jO.json user.KIDCAAw6Jz.json user.NhX8coGpJp.json user.QTVXLIAMSv.json user.tUy0REJWqL.json user.wxvYNu5eai.json
user.01F0Ikhr36.json user.6agHxaNYwT.json user.bac1JdzQHa.json user.ecKWuk28Lc.json user.hKkyoLhSia.json user.KIjBvPA4yI.json user.NHXXIqK3AG.json user.QtYRTkKrR2.json user.TV5NAiE6Tv.json user.WxXetkoE1m.json
user.01FTlmWn7H.json user.6AjPiwA3Ju.json user.BAdZ6YP1HT.json user.EcnhrwyWcA.json user.hkrd22DsWa.json user.kIMESPzPH0.json user.NIBNFgMPcg.json user.que3jpN0jb.json user.TvclAtvPym.json user.wxYKLHwQwr.json
user.01oeA9xN7u.json user.6AoptvJaW1.json user.baGRcUBjAb.json user.ecOT96ED2L.json user.HktJKo7OPp.json user.kIp4UHtFwE.json user.nIe77h4vDW.json user.qufxoaAKsS.json user.tVCv4ilp0P.json user.Wy0v9xF32n.json
user.01PpGWmHNm.json user.6bhENUwG8M.json user.bAgVR7jlW6.json user.ECSUUZLn91.json user.HKwbc2UZDS.json user.kiUiZvwhXJ.json user.NII9EYntLU.json user.QuhbyqAHIt.json user.tvKF6LfiR9.json user.Wy4m0EMuub.json
...
Benchmark sample set with and without dictionary compression
$ zstd -b1 -r github
1# 9114 files : 7484607 -> 2605179 (2.873), 190.3 MB/s , 528.3 MB/s
$ zstd --train -r github
Trying 5 different sets of parameters
k=1511
d=8
f=20
steps=4
split=75
accel=1
Save dictionary of size 112640 into file dictionary
$ ls
dictionary github github_users_sample_set.tar github_users_sample_set.tar.zst
$ zstd -b1 -r github -D dictionary
1# 9114 files : 7484607 -> 757000 (9.887), 645.0 MB/s ,1806.8 MB/s
Rebuild sample set archive
$ tar cf github_users_sample_set_rebuild.tar github
$ zstd -f --ultra -22 github_users_sample_set_rebuild.tar
github_users_sample_set_rebuild.tar : 3.40% (13742080 => 467550 bytes, github_users_sample_set_rebuild.tar.zst)
$ ls -la
-rw-rw-r-- 1 user user 13742080 Oct 20 2024 github_users_sample_set_rebuild.tar
-rw-rw-r-- 1 user user 467550 Oct 20 2024 github_users_sample_set_rebuild.tar.zst
-rw-rw-r-- 1 user user 23071232 Dec 8 2021 github_users_sample_set.tar
-rw-rw-r-- 1 user user 585218 Dec 8 2021 github_users_sample_set.tar.zst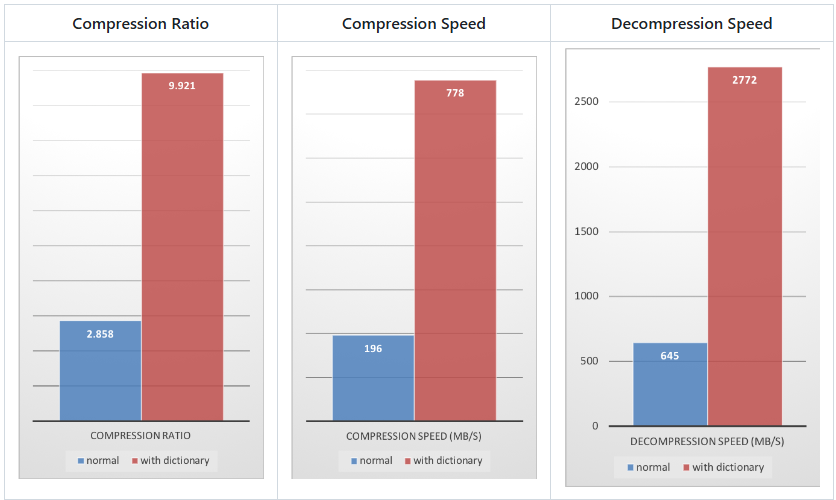
Adaptive compression
Zstandard는 데이터 특성에 따라 압축 방법을 적응적으로 선택한다.
데이터가 고도로 반복적인 경우에는 LZ77 방식이 주를 이루고, 데이터의 엔트로피가 높은 경우에는 FSE와 Huffman 코딩이 더 중요한 역할을 하게 된다.
메모리 효율성
Zstandard는 압축 및 해제 과정에서 메모리 사용을 최소화하도록 설계되었다.
압축 수준에 따라 메모리 사용량을 조정할 수 있으며, 메모리 제약이 있는 시스템에서도 적절한 수준의 성능을 제공할 수 있다.
참고
https://facebook.github.io/zstd/
https://github.com/facebook/zstd
https://engineering.fb.com/2016/08/31/core-infra/smaller-and-faster-data-compression-with-zstandard/
https://en.wikipedia.org/wiki/Zstd
https://datatracker.ietf.org/doc/html/rfc8878